슈퍼타입/서브타입 모델의 개요
Extented ER 모델이라고 부르는 이른바 슈퍼/서브타입 데이터 모델은 최근에 데이터 모델링을 할 때 자주 쓰이는 방법
이 모델이 자주 쓰이는 이유는
업무를 구성하는 데이터의 특징을 공통과 차이점의 특징을 고려하여 효과적으로 표현할 수 있기 때문이다.
즉, 공통의 부분을 슈퍼타입으로 모델링하고 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성에 대해서는
별도의 서브엔터티로 구분하여 업무의 모습을 정확하게 표현하면서 물리적인 데이터 모델로 변환을 할 때
선택의 폭을 넓힐 수 있는 장점이 있다. 이러한 장점 때문에 많은 프로젝트에서 슈퍼/서브 타입을 활용한
데이터 모델의 사례가 증가하고 있다.
물리적인 데이터 모델이 성능을 고려한 데이터 모델이 되어야 한다는 점을 고려하면 이렇게 막연하게 슈퍼/서브타입을
아무런 기준없이 변환하는 것 자체가 성능 저하가 될 수 있는 위험이 있음을 기억해야 한다.
슈퍼 / 서브타입 데이터 모델의 변환
성능을 고려한 슈퍼타입과 서브타입의 모델 변환의 방법을 알아보자.

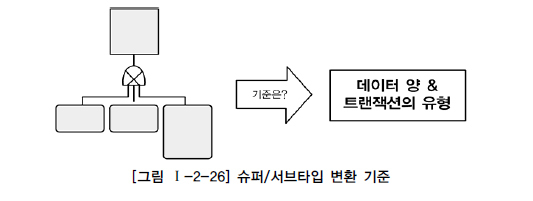
슈퍼/서브타입에 대한 변환을 잘못하면 성능이 저하되는 이유는 트랜잭션 특성을 고려하지 않고 테이블이 설계되었기 때문이다. 이것을 3가지 경우의 수로 정리하여 설명하면 다음과 같다.
- 논리데이터모델의 슈퍼타입과 서브타입 데이터 모델을 물리적인 테이블 형식으로 변환할때의 설명
- 트랜잭션은 항상 일괄로 처리하는데 테이블은 개별로 유지되어 Union 연산에 의해 성능이 저하될 수 있다.
- 트랜잭션은 항상 서브타입 개별로 처리하는데 테이블은 하나로 통합하여 변환하면 불필요하게 많은 양의
데이터가 집적되어 있어 성능이 저하될 수 있다. - 트랜잭션은 항상 슈퍼+서브 타입을 함께 처리하는데 개별로 유지하면 조인에 의해 성능이 저하될 수 있다.
인덱스 특성을 고려한 PK/FK 데이터베이스 성능 향상
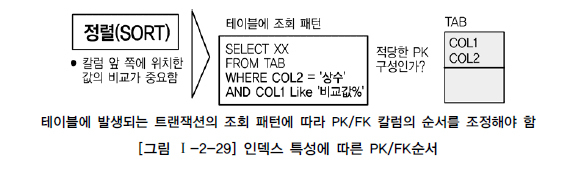
PK/FK 칼럼 순서와 성능개요 데이터를 조회할 때 가장 효과적으로 처리될 수 있도록 접근경로를 제공하는 오브젝트가
바로 인덱스이다. 일반적으로 데이터베이스 테이블에서는 균형잡힌 트리구조의 B* Tree 구조를 많이 사용한다.
일반적으로 프로젝트에서는 PK/FK 칼럼 순서의 중요성을 인지하지 못한 채로 데이터 모델링이 되어 있는 그 상태대로 바로 DDL을 생성함으로서 데이터베이스 데이터처리 성능에 문제를 유발하는 경우가 빈번하게 발생이 된다.
# Reference:
데이터베이스 구조와 성능
1. 슈퍼타입/서브타입 모델의 성능고려 방법 가. 슈퍼/서브타입 데이터 모델의 개요 Extended ER모델이라고 부르는 이른바 슈퍼/서브타입 데이터 모델은 최근에 데이터 모델링을 할 때 자주 쓰이는
dataonair.or.kr
'Language > RDBMS' 카테고리의 다른 글
| SQL 함수 (0) | 2023.03.08 |
|---|---|
| 분산 데이터베이스의 성능 (0) | 2023.03.07 |
| 대량 데이터에 따른 성능 (0) | 2023.03.07 |
| 반정규화와 성능 (0) | 2023.03.07 |
| 정규화와 성능 (0) | 2023.03.07 |