

Epochs:
하나의 에포크는 훈련 데이터 셋의 샘플이 훈련 모델을 통해 적어도 한번은 공급되었음을 의미한다.
예를 들어, 에포크가 50으로 설정되어 있다면, 그것은 훈련하고 있는 모델이
전체 훈련 데이터 셋에서 50번 작동한다는 것을 의미함.
일반적으로 숫자가 클수록 모형이 데이터를 더 잘 예측하는 방법으로 학습
모형을 사용하여 좋은 예측 결과를 얻을 때까지 이 에포크 값을 조정함(일반적으로 증가)
Batch Size:
배치는 한 번의 훈련 반복에 사용되는 샘플의 집합이다.
예를 들어 이미지가 80개이고 배치 크기를 16개를 선택했다고 가정한다.
즉, 데이터가 80 / 16 = 5 배치로 분할하게 된다.
총 5개의 배치가 모두 모델을 통해 공급되면 정확히 1개의 에포크가 완료된다.
좋은 결과를 얻기 위해 이 숫자를 조정할 필요는 없다.
Learning Rate:
이 숫자를 수정할 때는 주의해야 한다.
작은 차이도 모델의 학습에 큰 영향을 미칠 수 있다.
from keras.models import load_model
from PIL import Image, ImageOps #Install pillow instead of PIL
import numpy as np
# Disable scientific notation for clarity
np.set_printoptions(suppress=True)
# Load the model
model = load_model('keras_Model.h5', compile=False)
# Load the labels
class_names = open('labels.txt', 'r').readlines()
# Create the array of the right shape to feed into the keras model
# The 'length' or number of images you can put into the array is
# determined by the first position in the shape tuple, in this case 1.
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
# Replace this with the path to your image
image = Image.open('<IMAGE_PATH>').convert('RGB')
#resize the image to a 224x224 with the same strategy as in TM2:
#resizing the image to be at least 224x224 and then cropping from the center
size = (224, 224)
image = ImageOps.fit(image, size, Image.Resampling.LANCZOS)
#turn the image into a numpy array
image_array = np.asarray(image)
# Normalize the image
normalized_image_array = (image_array.astype(np.float32) / 127.0) - 1
# Load the image into the array
data[0] = normalized_image_array
# run the inference
prediction = model.predict(data)
index = np.argmax(prediction)
class_name = class_names[index]
confidence_score = prediction[0][index]
print('Class:', class_name, end='')
print('Confidence score:', confidence_score)import cv2
import numpy as np
from keras.models import load_model
# Load the model
model = load_model('keras_model.h5')
# CAMERA can be 0 or 1 based on default camera of your computer.
camera = cv2.VideoCapture(0)
# Grab the labels from the labels.txt file. This will be used later.
labels = open('labels.txt', 'r').readlines()
while True:
# Grab the webcameras image.
ret, image = camera.read()
# Resize the raw image into (224-height,224-width) pixels.
image = cv2.resize(image, (224, 224), interpolation=cv2.INTER_AREA)
# Show the image in a window
cv2.imshow('Webcam Image', image)
# Make the image a numpy array and reshape it to the models input shape.
image = np.asarray(image, dtype=np.float32).reshape(1, 224, 224, 3)
# Normalize the image array
image = (image / 127.5) - 1
# Have the model predict what the current image is. Model.predict
# returns an array of percentages. Example:[0.2,0.8] meaning its 20% sure
# it is the first label and 80% sure its the second label.
probabilities = model.predict(image)
# Print what the highest value probabilitie label
print(labels[np.argmax(probabilities)])
# Listen to the keyboard for presses.
keyboard_input = cv2.waitKey(1)
# 27 is the ASCII for the esc key on your keyboard.
if keyboard_input == 27:
break
camera.release()
cv2.destroyAllWindows()
from keras.models import load_model
model = load_model('keras_model.h5')
model.summary()
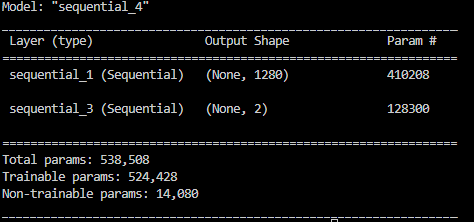
"""
sequential_1 (Sequential) (None, 1280) 410208
sequential_3 (Sequential) (None, 2) 128300
=================================================================
Total params: 538,508
Trainable params: 524,428
Non-trainable params: 14,080
_________________________________________________________________
"""
케라스는 layer를 model에 순차적으로 저장하고 있음.
model에 저장한 다음 위와 같은 코드 입력시 전반적인 구조를 확인 할 수 있음.
https://github.com/gaussian37/netron
GitHub - gaussian37/netron: Visualizer for deep learning and machine learning models
Visualizer for deep learning and machine learning models - GitHub - gaussian37/netron: Visualizer for deep learning and machine learning models
github.com
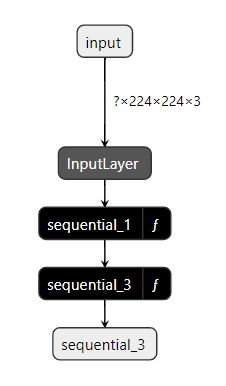
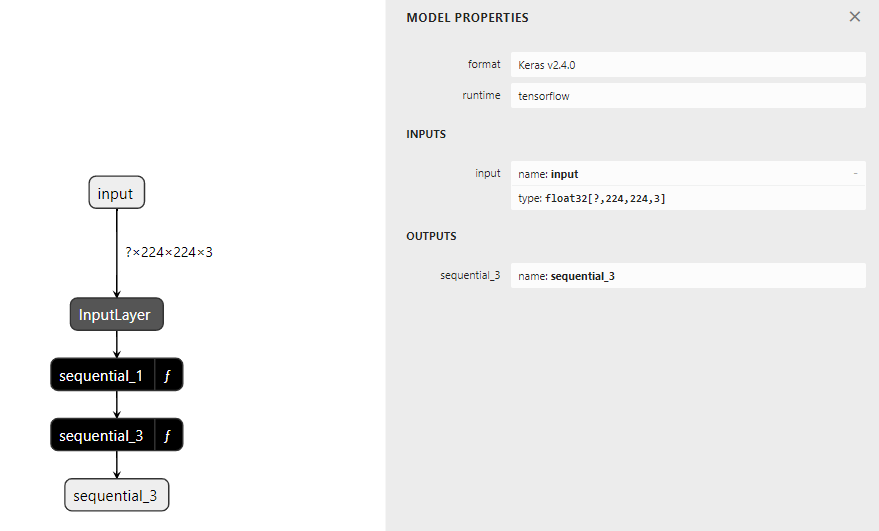
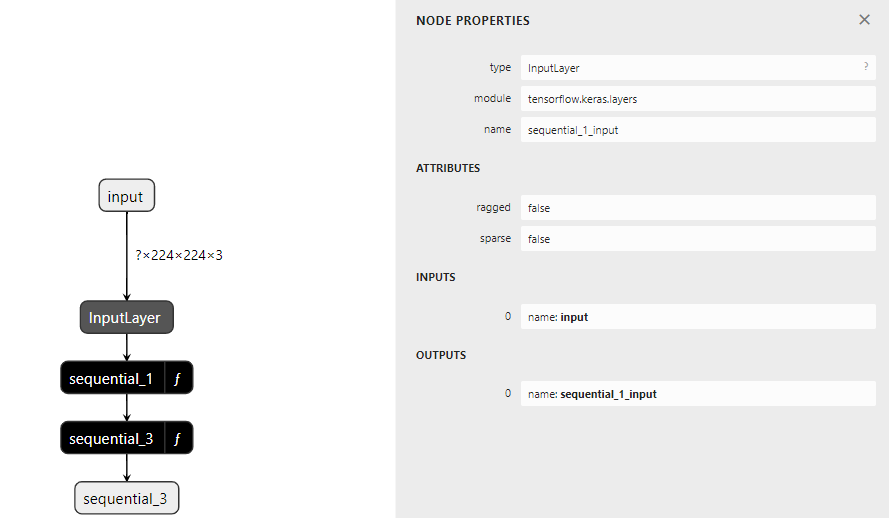
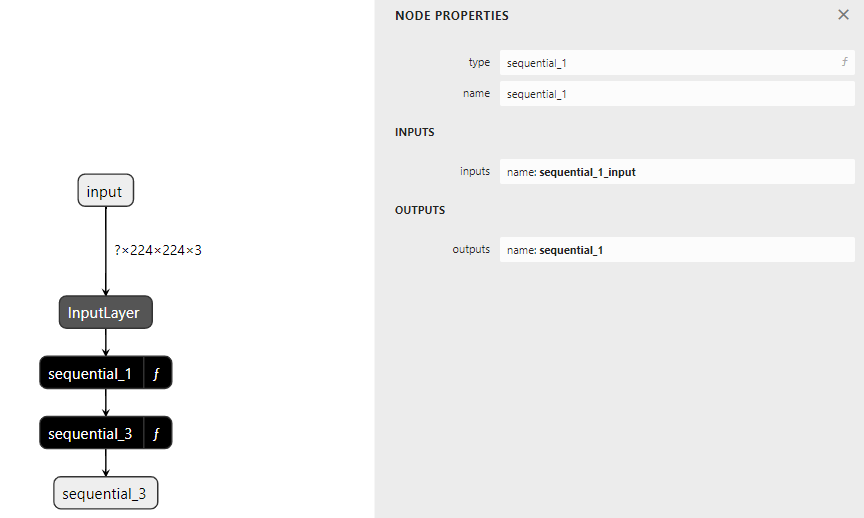
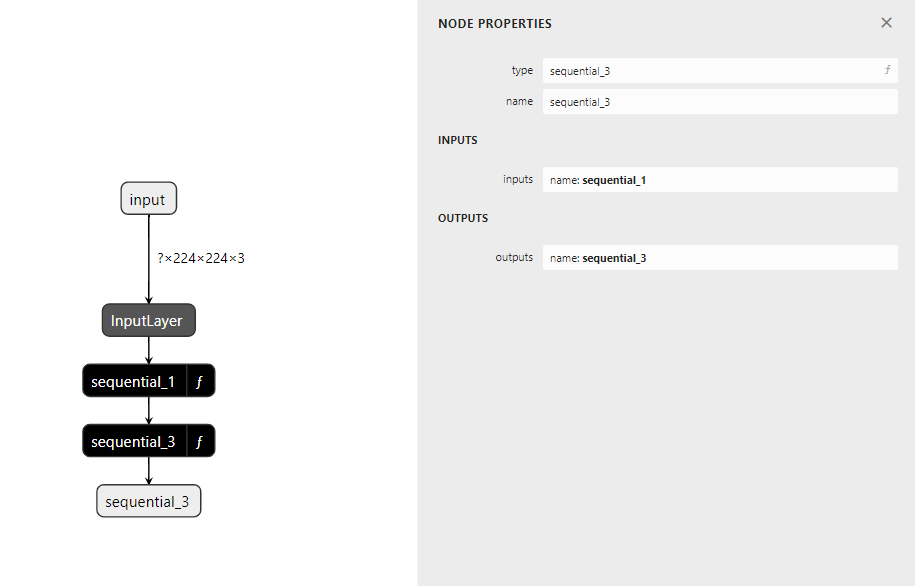

sequential_1 (function)

'Deep Learning' 카테고리의 다른 글
| 1. Setting up the environment for ML (0) | 2023.09.18 |
|---|---|
| Reinforcement 'CartPole-v1' (0) | 2022.09.23 |
| Reinforcement Learning (0) | 2022.09.19 |
| Calculating a Function (0) | 2022.09.16 |
| Linear Models_MLBasic.03 (0) | 2022.09.16 |