1. Load DataSet
인공지능 모델을 만드려면 훈련(train)데이터와 검증(test) 데이터가 필요함.
> (x_train, y_train), (x_test, y_test) = mnist.load_data()
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print("x_train shape", x_train.shape)
print("y_train shape", y_train.shape)
print("x_test shape", x_test.shape)
print("y_test shape", y_test.shape)
"""
x_train shape (60000, 28, 28)
y_train shape (60000,)
x_test shape (10000, 28, 28)
y_test shape (10000,)
"""
mnist 데이터셋에는 load_data() 라는 함수가 포함되어 있는데 mnist 데이터셋에서 데이터를 불러오라는 명령어입니다.
mnist 데이터는 이미 네 부분으로 나뉘어 있는데,
첫 번째 부분을 x_train 으로,
두 번째 부분을 y_train 으로,
세 번째 부분을 x_test 로,
네 번째 부분을 y_test로 불러오라는 명령어 입니다.
그리고 이 값들은 모두 넘파이 라이브러리를 사용하여 만든 값입니다.
앞으로 이 값들을 사용할 때 넘파이 라이브러리의 다양한 함수,
예를 들어 데이터의 형태를 바꾸는 reshape 함수 같은 여러 함수를 사용할 수 있습니다.
mnit 데이터셋은 훈련데이터와 검증데이터로 구성되어 있습니다.
훈련 데이터에는 각 손글씨 그림과 그 그림이 어떤 숫자를 의미하는지(정답) 이 있으며
검증 데이터에도 마찬가지입니다.
> print("x_train shape", x_train.shape)
파이썬 명령어 중 print문을 사용하여 x_train 데이터의 형태를 출력하는 명령어입니다.
shape 명령어는 numpy library 에서 사용하는 데이터의 형태를 볼 수 있는 명령어입니다.
"x_train" 데이터에는 총 60,000개의 데이터가 있으며,
각 데이터에는 가로 28개, 세로 28개의 데이터가 있으므로 데이터의 모습은 (60000, 28, 28) 입니다.

이 중에서 첫번째 데이터의 실제 모습이 위 그림입니다.
검은색은 0, 흰색은 255, 회색은 1 ~ 254 사이의 숫자로 나타내며,
가로 28개의 숫자, 세로 28개의 숫자로 이루어진 것을 볼 수 있습니다.
* dtype 은 uint8 이며 이는 0 ~255 개의 숫자까지 표현이 가능하다.
> print("y_train shape", y_train.shape)
print문을 사용하여 y_train 데이터의 형태를 출력하는 명령어입니다.
y_train 데이터는 x_train 데이터의 정답이라고 생각하면 됩니다.
x_train 데이터 개수가 60,000개 였으니 y_train 데이터 또한 60,000개입니다.
y_train shape (60000,)데이터의 개수가 60,000개이며, 그 뒷부분에는 아무런 정보가 없습니다.
이렇게 콤마(,) 이후에 아무것도 나오지 않으면 이는 1차원 배열을 의미합니다.
실제 y_train 데이터를 살펴보면 첫번째 7은 x_train 중 1번째 데이터의 값이 무엇인지 나타내고 있습니다.
> print("x_test shape ", x_test.shape)
print문을 사용하여 x_test 데이터의 형태를 출력하는 명령어로, 결과값은 x_test shape(10000, 28, 28) 입니다.
x_test shape (10000, 28, 28)x_train 데이터와 다른점은 데이터의 총개수입니다.
> print("y_test shape", y_test.shape)
print문을 사용하여 y_test 데이터의 형태를 출력하는 명령어로, 결과값은 y_test shape(10000, ) 입니다.
y_test shape (10000,)
2. Replace the shape of X in the "mnist" dataset
28 x 28 형태의 데이터를 인공지능 모델에 넣으려면 형태를 바꿀 필요가 있습니다.
이제부터 만들 인공 신경망의 입력층에 데이터를 넣을 때는 한 줄로 만들어서 넣어야 하기 때문입니다.
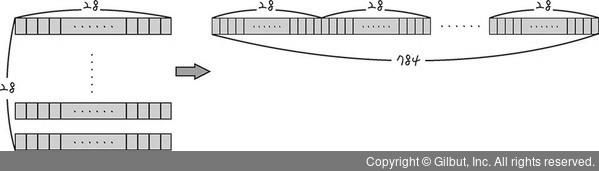
우리가 준비한 데이터의 모습은 28 x 28 모습입니다.
이 데이터를 1 x 784 형태처럼 한줄로 만든 후 이를 딥러닝 모델에 입력하려 합니다.
X_train = x_train.reshape(60000, 784)
X_test = x_test.reshape(10000, 784)
print("X Training matrix shape", X_train.shape)
print("X Testing matrix shape", X_test.shape)
"""
X Training matrix shape (60000, 784)
X Testing matrix shape (10000, 784)
"""> X_train = x_train.reshape(60000, 784)
> X_test = x_test..reshape(10000,784)
28 x 28 형태인 데이터를 1 x 784로 바꾸는 명령어입니다.
이때 사용하는 reshape 명령어는 넘파이의 명령어입니다.
이 명령어를 사용하면 데이터의 형태를 원하는 대로 바꿀 수 있습니다.
784는 28 x 28 을 한 값입니다.
> X_train = X_train.astype("float32")
> X_test = X_test.astype("float32")
타입 변환 전 정수형 "uint8"을 실수형 "float32"로 바꾸게 됨.
이제부터는 정규화하기 위해 데이터를 0 ~ 1 사이의 값으로 바꿔 주려고 합니다.
이 값들은 모두 실수값인데 지금 가진 X_train 데이터는 정수형이기 때문에 자료형을 바꿔 주어야 합니다.
이를 위해 X_train 데이터의 형태를 실수형태로 바꾸고 그 데이터를 다시 X_train 변수에 넣습니다.
Numpy의 데이터 타입 확인:
2022.09.06 - [Programming/Python] - How to use Numpy
> X_train /= 255
> X_test /= 255
앞에서 mnist 데이터의 각 형태를 살펴보았듯이
검은색은 0, 흰색은 255, 회색은 1 ~ 254 사이의 값으로 이루어져 있습니다.
이를 0 ~ 1사이의 값으로 바꾸는 방법은 바로 255로 나누는 것입니다.
X_train, test 각 데이터를 255로 나눈 값을 다시 저장하는 코드입니다.
3. Replace the shape of Y in the "mnist" dataset
지금부터 y_train 데이터와 y_test 데이터의 형태를 바꾸겠습니다.
인공지능이 분류를 잘 할수 있도록 하기 위해서입니다.
우리가 만들고 있는 인공지능은 이미지를 0 ~ 9 사이의 숫자로 분류하는 인공지능입니다.
이를 다시 살펴보면 인공지능은 이미지가 가진 숫자의 특성,
즉 "이 숫자는 3이고 2보다 1보다 더 큰 수이다." 와 같은 특성을 알 필요는 없습니다.
우리가 만드는 인공지능의 목표는 3과 2를 잘 구분하면 되는 것이죠.
그러므로 이미지의 Label(정답)을 인공지능에게 0, 1, 2, 3, 4.. 와 같이 숫자로 알려주는 것이 아니라
더 잘 구분할 수 있는 방법으로 알려줄 필요가 있습니다.
바로 0은 0이라는 숫자의 의미보다 인공지능이 구분할 10개의 숫자 중 첫번째 숫자로
1 은 1 이라는 숫자의 의미보다 두번째 숫자로 말해주는 것이죠.
이를 조금 어려운 말로 표현하면 수치형 데이터를 범주형 데이터로 변환하는 것이라고 말할 수 있습니다.
이와 같이 몇 번째라는 식으로 알려주면 인공지능은 더 높은 성능으로 분류할 수 있습니다.
그래서 예측이 아닌 Classification 문제는 대부분 정답 Label을
첫 번째, 두 번째, 세 번째와 같이 순서로 나타내도록 데이터의 형태를 바꿉니다.
이때 사용하는 방법이 바로 One-Hot Encoding 입니다.
Y_train = tf.keras.utils.to_categorical(y_train, 10) #to_categorical
Y_test = tf.keras.utils.to_categorical(y_test, 10)
print("Y Training matrix shape", Y_train.shape)
print("Y Testing matrix shape", Y_test.shape);
#Y Training matrix shape (60000, 10)
#Y Testing matrix shape (10000, 10)> Y_train = to_categorical(y_train, 10)
> Y_test = to_categorical(y_test, 10)
Y_train 데이터를 원-핫 인코딩합니다.
이 때 사용하는 Function이 Tensorflow의 Keras 내부의 utils도구 중 to_categorical 입니다.
( = tf.keras.utils.to_categorical )
해당 함수는 수치형 데이터를 범주형 데이터로 만들어 주는 함수입니다.
함수를 사용하기 위해서는 변경 전 데이터 (y_train)와 원-핫 인코딩할 숫자,
즉 몇개로 구분하고자하는지가 필요합니다.
인공지능이 예측하는 결과는 0 ~ 9까지의 숫자이므로 분류하고자 하는 값은 열 개입니다.
따라서 One-Hot Encoding을 위해 구분하려는 숫자를 10으로 설정합니다.
원-핫 인코딩 결과 Y_train 데이터가 다음과 같은 형태로 바뀌었습니다.
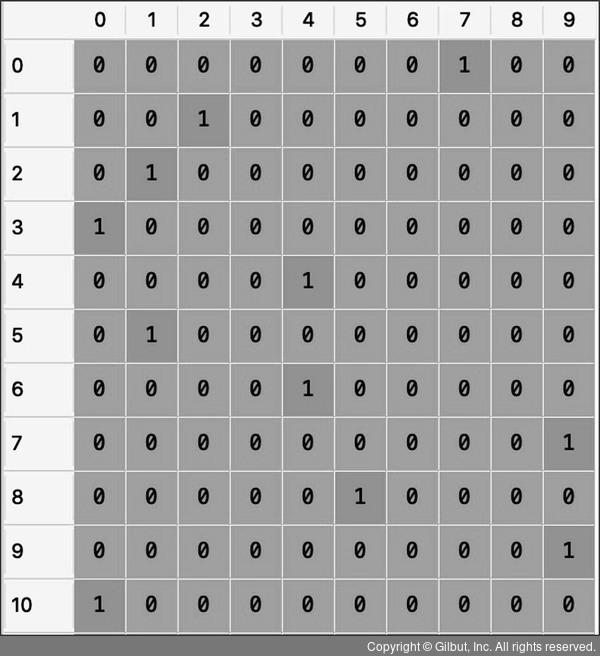
첫 번째 데이터에는 7에서 [0, 0, 0, 0, 0, 0, 0, 1, 0, 0] 으로 바뀌었습니다.
여덟 번째에만 1로 표시된 모습을 볼 수 있는데 0, 1, 2, 3, 4, 5, 6, 7에서 7의 위치가 여덟 번째이기 때문입니다.
print("Y Training matrix shape", Y_train.shape)
print("Y Testing matrix shape", Y_test.shape)
#Y Training matrix shape (60000, 10)
#Y Testing matrix shape (10000, 10)해당 위치까지 입력한 이후 프린트를 해보았을 때.
Y_train 데이터의 형태를 출력하게 되면 결과값이 (60000,) 에서 (60000, 10)으로 바뀜
각 행의 데이터 수가 1개에서 10개로 늘어났기 때문입니다.
Y_test 데이터의 형태 또한 출력 결과값이 (10000, 10) 으로 바뀐 값이 출력됨.
4. Designing an AI Model
우리가 설계하고 있는 인공지능 모델은 4개의 층으로 이루어졌습니다.
첫 번째 층은 입력층이며 데이터를 넣는 곳입니다.
두 번째와 세 번째 층은 은닉층입니다.
마지막 네 번째 층은 결과가 출력되는 출력층입니다.
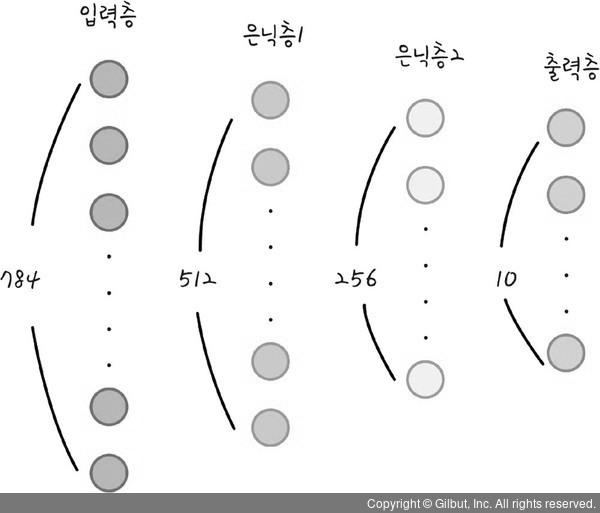
Input layer 의 Neural 수는 784개
우리가 넣는 데이터의 모습이 784개(=28 x 28px)의 데이터가 한 줄로 이루어져있기 때문입니다.
이제 이 데이터를 딥러닝 모델에 넣을 예정이며,
① 첫 번재 은닉층의 노드는 512개로 해보겠습니다.
그리고 첫 번째 은닉층에서 두 번째 은닉층으로 갈때
Activation Function은 Relu Function을 사용할 예정입니다.
*Relu 함수는 활성화 함수중 하나이며,0 보다 작은 값이 입력되면 0을 반환하고,0 보다 큰 값이 입력되면 그 값을 그대로 반환하는 함수입니다.시그모이드 함수에 비해 학습이 더 잘 되기 때문에 최근 많이 사용하고 있습니다.
② 두 번째 은닉층의 노드는 256개로 해보겠습니다.
여기에서 마지막 층으로 갈 때에도 Activaiton Function은 Relu Function을 사용할 예정입니다.
③ 마지막 노드가 10개인 이유는 입력된 이미지를 10개로 구분하기 위해서입니다.
그리고 가장 높은 확률의 값으로 분류하기 위해서각 노드의 최종 값을 Softmax Function을 사용하여 나타냅니다.
*Softmax 함수는 입력된 여러 값을 0 ~ 1 사이의 모든 값으로 모두 정규화하며 출력하는 함수입니다.
그리고 그 출력값들의 합은 항상 1이 되는 특성이 있습니다.
그래서 분류 문제에서 어떤 범주를 가장 높은 확률로 예측하는지 살펴보는 데 주로 사용합니다.
# Model.(Common)
"""
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(512, input_shape=(784, )))
model.add(tf.keras.layers.Activation('relu'))
model.add(tf.keras.layers.Dense(256))
model.add(tf.keras.layers.Activation('relu'))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax'))
model.summary()
"""
"""
=================================================================
Total params: 535,818
Trainable params: 535,818
Non-trainable params: 0
_________________________________________________________________
"""
# Model. (abbreviation)
"""
model = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(784, )),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
"""
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 401920
dense_1 (Dense) (None, 256) 131328
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 535,818
Trainable params: 535,818
Non-trainable params: 0
_________________________________________________________________
"""> model = tf.keras.Sequential()
우리는 이 인공지능 모델을 Sequential 방식으로 개발합니다.
Keras는 Sequential Model을 통해 이러한 형태의 Deep Learning Model 을 쉽게 개발할 수 있도록 도와줍니다.
지급부터 딥러닝에 사용할 Model을 Sequential 로 정의합니다.
> model.add(tf.keras.layers.Dense(Number of Node, input_shape = (Data shape, )))
Model 에 층을 추가합니다.
추가하는 명령어는 add입니다.
바로 앞에서 만든 딥러닝 모델이 가지고 있는 함수를 사용하기 때문에 model 뒤에 점을 찍은 후 add 함수를 적습니다.
이때 층이 어떤 형태인지를 설정하기 위해 Dense 함수를 사용합니다.
Dense 함수의 Arguments
첫 번째 Argument는 해당 Hidden-Layer의 노드 수이며,
두 번재 Argument인 input_shape는 입력하는 데이터의 형태입니다.
> model.add(tf.keras.layers.Activation('relu || softmax')
다음 층으로 값을 전달 할 때 어떤 Activation Function 를 사용하여 전달할지를 결정합니다.
보통 Hidden-layer 에서는 Relu 함수를, Output-layer로는 Softmax 함수를 사용합니다.
> model.summary()
summary 함수는 모델이 어떻게 구성되었는지 살펴보는 함수입니다.
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 401920
dense_1 (Dense) (None, 256) 131328
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 535,818
Trainable params: 535,818
Non-trainable params: 0
_________________________________________________________________
"""
일단 Sequential Model로 구성되어 있습니다.
레이어를 나타내는 Layer 부분과
레이어의 모습을 나타내는 Output Shape 부분
각 노드와 편향을 연결하는 가중치의 수를 나타내는 Params 부분으로 나누어져 있습니다.
첫 번째 레이어는 512개 노드로 이루어져 있으며,
총 401,920 (784 x 512 + 512) 개의 parameter 로 이루어져 있습니다.
바로 784개 입력층에서 512개 은닉층으로 각각 연결되어 있어서 784 x 512개 만큼 가중치(w)가 있고,
은닉층 각 노드 수만큼 편향(b) 512개가 있기 때문입니다.
두번째 레이어는 256개의 노드로 이루어져 있으며,
총 131,328 (512 x 256 + 256) 개의 parameter 로 이루어져 있습니다.
마지막 레이어는 0 부터 9까지의 수를 구분하기 위한 10개 노드로 이루어져 있으며,
총 2,570 (256 x 10 + 10) 개의 parameter 로 이루어져 있습니다.
5. Train a model
모델을 설계한 후 할 일은 이 모델을 실행하는 것입니다.
심층 신경망에 데이터를 흘려보낸 후 정답을 예측할 수 있도록 신경망을 학습하는 과정이 필요합니다.
바로 딥러닝을 할 차례입니다.
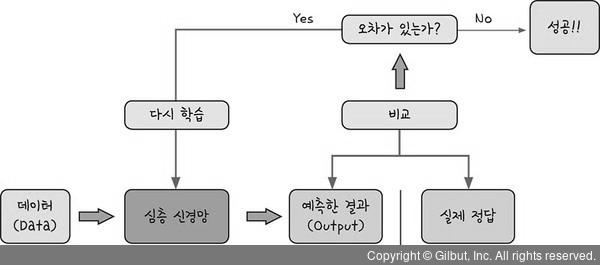
위와 같이 데이터를 사용하여 심층 신경망을 딥러닝 기법으로 학습시킵니다.
이때 신경망이 예측한 결과와 실제 정답을 비교한 후 오차가 있다면 다시 신경망을 학습시키는 과정을 거칩니다.
오차가 없다면 더 학습시킬 필요는 없지만 웬만하서는 오차가 0으로 나오는 경우는 거의 없습니다.
보통 학습시키는 횟수를 정해 준 후 그만큼만 학습시킵니다.
이처럼 신경망을 잘 학습시키려면 학습한 신경망이 분류한 값과 실제 값의 오차부터 계산해야 합니다.
그리고 오차를 줄이기 위해 경사 하강법(Gradient Descent)을 사용합니다.
지금부터 모델을 학습시켜 봅시다.
#compile
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, Y_train,
batch_size = 128,
epochs = 10,
verbose = 1)
"""
Epoch 1/10
469/469 [==============================] - 3s 5ms/step - loss: 0.2277 - accuracy: 0.9339
Epoch 2/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0835 - accuracy: 0.9745
Epoch 3/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0521 - accuracy: 0.9840
Epoch 4/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0354 - accuracy: 0.9886
Epoch 5/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0273 - accuracy: 0.9914
Epoch 6/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0205 - accuracy: 0.9932
Epoch 7/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0159 - accuracy: 0.9950
Epoch 8/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0168 - accuracy: 0.9944
Epoch 9/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0156 - accuracy: 0.9946
Epoch 10/10
469/469 [==============================] - 3s 6ms/step - loss: 0.0120 - accuracy: 0.9963
"""
첫 번째 epoch 부터 열 번째 epoch로 갈수록 오차값(loss)이 줄어드는 모습을 확인할 수 있습니다.
정확도(accuracy) 또한 지속적으로 증가하는 것을 볼 수 있습니다.
> model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
Keras는 심층 신경망의 학습하는 방법을 정하는 명령어를 제공합니다.
그 명령어는 바로 compile 함수입니다.
이 함수를 사용하기 위해서는 몇 가지 규칙이 있습니다.
# model.compile Function
첫 번째로는 오차값을 계산하는 방법을 알려줘야 합니다.
이 인공지능은 이미지를 10개 중 하나로 분류해야 하므로 다중 분류 문제에 해당합니다.
그렇기 때문에 categorical_crossentropy 방법을 사용하면 됩니다.
두 번째로는 오차를 줄이는 방법을 알려줘야 합니다.
오차를 줄이기 위해 optimizer(최적화)를 사용하면 됩니다.
optimizer에는 다양한 방법이 있지만 여기에서는 adam 이라는 방법을 사용합니다.
* What is Optimizer ?
딥러닝을 통해 인공지능 모델을 학습시킬 때 발생하는 오차를 줄이기 위해 Gradient Descent 이라는 알고리즘을 사용합니다.
이때 Gradient Descent 를 어떠한 방식으로 사용할지 다양한 알고리즘이 있는데
그러한 알고리즘들을 Keras에서 모아 놓은 것이 바로 Optimizer Library 입니다.
Optimizer 의 종류에는 adam 뿐만 아니라 stochastic gradient descent 등이 있습니다.
마지막으로는 학습결과는 어떻게 확인할지 알려줘야 합니다.
여기에서는 정확도로 모델의 학습 결과를 확인해보겠습니다.
정확도(accuracy)는 실제 60,000개 데이터의 예측 결과와 실제 값을 비교해 본 후 정답 비율을 알려줍니다.
> model.fit(X_train, Y_train,
batch_size = 128,
epochs = 10,
verbose = 1)
이제 실제로 학습시킬 차례입니다.
Keras는 학습시키기 위해 '맞춘다'라는 의미를 가진 fit 함수를 제공합니다.
이 함수를 사용하려면 마찬가지로 규칙을 따라야 합니다.
# model.fit Function
첫 번째로 입력할 데이터를 정합니다.
우리는 X_train, Y_train 데이터를 사용하여 인공지능 모델을 학습시키기 때문에 이 두가지를 넣습니다.
두 번째로 배치사이즈(batch_size)를 정합니다.
배치 사이즈란 인공지능 모델이 한 번에 학습하는 데이터의 수를 의미합니다.
여기에서는 한 번에 128개 데이터를 학습시키겠습니다.
즉, 배치 사이즈는 128로 하겠습니다.
세 번째로 에포크(epochs)를 정합니다.
에포크는 모든 데이터를 1번 학습하는 것을 의미합니다.
여기에서는 모든 데이터를 10번 반복해서 학습시키겠습니다.
다섯 번째로 verbose를 설정합니다.
verbose는 Keras의 fit 함수의 결과값을 출력하는 방법으로 1로 설정하였습니다.
verbose = 0 : 아무런 표시를 하지 않음
verbose = 1 : 에포크별 진행 상황을 알려줌
verbose = 2 : 에포크별 학습 결과를 알려줌
* 실행 결과는 컴퓨터 환경마다 차이가 있음
6. To check model accuracy
지금까지 심층 신경망 모델을 설계하고, 그 모델을 학습시켰습니다.
이제 그 모델의 성능이 어느 정도인지 확인해 보아야 합니다.
지금부터 인공지능 모델이 얼마나 잘 학습하였는지 시험해 보겠습니다.
시험 내용은 ' 검증 데이터를 얼마나 잘 맞히는가 ' 입니다.
# To check model accuracy
score = model.evaluate(X_test, Y_test)
print("Test score : ", score[0])
print("Test accuracy : ", score[1])
"""
313/313 [==============================] - 1s 2ms/step - loss: 0.0703 - accuracy: 0.9817
Test score : 0.07032162696123123
Test accuracy : 0.9817000031471252
"""
> score = model.evaluate(X_test, Y_test)
Keras의 evaluate 함수는 모델의 정확도를 평가할 수 있는 기능을 제공합니다.
이 함수를 사용하려면 두 가지 데이터를 넣어야 합니다.
첫 번째 데이터는 테스트할 데이터로 여기에서는 X_test를 입력합니다.
두 번째 데이터는 테스트할 데이터의 정답으로 여기에서는 Y_test를 입력합니다.
evaluate 함수에 데이터를 넣으면 두가지 결과를 보여주는데
첫 번째는 바로 오차값(loss) 입니다.
오차값은 0 ~ 1 사이의 값으로,
0 이면 오차가 없는 것이고
1 이면 오차가 아주 크다는 것을 의미합니다.
두번째는 정확도(accuracy) 입니다.
모델이 예측한 값과 정답이 얼마나 정확한지에 대해서 0과 1 사이의 값으로 보여줍니다.
1에 가까울 수록 정답을 많이 맞춘 것을 의미합니다.
생성한 모델에 X_test, Y_test 데이터를 입력하여 얻은
두가지 결과값인 오차와 정확도를 score 변수에 넣습니다.
> print("Test score : ", score[0])
score 변수에는 오차값과 정확도가 들어 있습니다.
여기에서는 오차값을 출력하기 위해 score 변수의 첫 번째 항목인 점수를 출력합니다.
> print("Test accuracy : ", score[1])
score 변수의 두 번째 항목인 정확도를 출력합니다.
최종 오차는 0.07, 정확도는 0.98이 나온 것을 확인할 수 있습니다.
7. To check model learning results
지금까지 심층 신경망 모델의 구조를 만들고 그 모델을 학습시킨 후, 학습 결과까지 살펴보았습니다.
사실 여기까지만해도 이미 인공지능을 만든 것입니다.
하지만 실제로 인공지능이 어떤 그림을 무엇으로 예측했는지 궁금하지 않나요?
지금부터는 인공지능이 잘 구분한 그림과 잘 구분하지 않은 그림을 살펴보겠습니다.
import numpy as np
predicted_classes = np.argmax(model.predict(X_test), axis=1)
correct_indices = np.nonzero(predicted_classes == y_test)[0]
incorrect_indices = np.nonzero(predicted_classes != y_test)[0]> predicted_classes = np.argmax(model.predict(X_test), axis=1)
우리가 만든 인공지능 모델인 model에서 결과를 예측하는 함수인 predict 함수에 X_test 데이터를 입력해 보겠습니다.
X_test 데이터의 개수가 몇개였는지 기억나나요? 10,000개 였습니다.
따라서 예측한 값 또한 10,000개가 나오며 그 모습은 다음과 같습니다.

각 입력 데이터를 보고 인공지능이 0 부터 9 까지의 수 중에서 어떤 수로 예상하는지 알려주는 모습입니다.
첫 번째 줄에서는 인덱스 값에 6에 0.6이라는 값이 들어 있습니다.
나머지 숫자는 그보다 작은 숫자들이 있습니다.
이는 인공지능 모델이 이미지를 보고, 그 이미지가 숫자 6일 확률이 가장 높다고 생각한 것 입니다.
이렇게 예상한 모습이 총 10,000개가 있습니다.
이러한 모습으로 출력될 수 있었던 이유는 Softmax Function 을 사용하였기 때문입니다.
* Softmax 함수를 사용하면 출력값을 0부터 1까지의 숫자 중 하나로 변환해 줍니다.
그리고 모든 출력값을 더하면 1이 된다는 특징이 있습니다.
그렇다면 우리가 만든 인공지능은 결과를 무엇이라고 나타내어야 할까요?
바로 가장 높은 확률이 나온 6이겠죠?
이때 Numpy의 argmax 함수를 사용합니다.
argmax 함수는 여러 데이터 중에서 가장 큰 값이 어디에 있는지를 나타내기 때문입니다.
이때 기준을 정해주는 것이 바로 axis 입니다.
axis = 0 은 각 열(세로)에서 가장 큰 수를 고르는 것이고axis = 1은 각 행(가로)에서 가장 큰 수를 고르는 것입니다.
그 결과 첫 번째 넣은 데이터의 정답이 6이라는 것을 알 수 있습니다.이제 argmax 함수를 사용하여 인공지능 모델이 예측한 모든 값을 predicted_classes 변수에 넣겠습니다.
> correct_indices = np.nonzero(predicted_classes == y_test)[0]
인공지능이 잘 예측한 숫자의 모습이 무엇인지 찾아보겠습니다.
이 과정은 생각보다 복잡합니다.
먼저 실제 값과 예측 값이 일치하는 값을 찾아내어 correct_indices 변수에 저장하는 과정입니다.
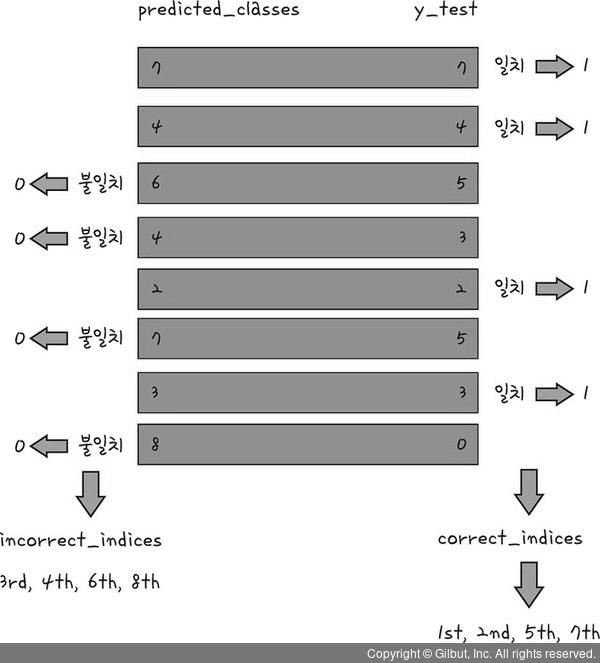
논리 연산자를 사용하여 예측 값(predicted_classes)과 실제값(y_test)을 비교해보겠습니다.
먼저 두 개의 값이 일치하는 값을 찾아보겠습니다.
즉, 어떤 그림을 정확하게 예측하였는지 살펴보는 과정입니다.
논리 연산의 결과 두 값이 같으면 1(True), 같지 않으면 0(False)가 나옵니다.
위 코드에서는 예측한 결과값과 실제 결과값의 데이터를 비교하여 결과가 같으면 1, 다르면 0이 나옵니다.
같은 값을 찾기 위해서 10,000개의 수 모두를 하나하나 확인하기란 쉽지 않은 일입니다.
이 때 사용할 수 있는 함수가 바로 Numpy 함수의 nonzero 함수입니다.
nonzero 함수는 Numpy 배열에서 0이 아닌 값,
즉 여기에서는 1 (인공지능이 예측한 값과 정답이 일치하는 수) 을 찾아내는 함수입니다.
이 함수를 사용하면 다음과 같이 정확하게 예측한 데이터의 위치를 알아냅니다.
이제 nonzero 함수를 사용하여 0 아닌 값 (여기에서는 1인 값)을 찾아줍니다.
이때 정확하게 데이터의 위치,
즉 첫 번째, 두 번째, 다섯 번째, 일곱 번째 , ... 를 correct_indices 변수에 넣어줍니다.
> incorrect_indices = np.nonzero(predicted_classes != y_test)[0]
이제 인공지능이 예측하지 값은 무엇이며, 그 숫자는 어떤 모양인지를 찾아보겠습니다.
앞의 과정과 비슷하지만 조금 다른 점이 있습니다.
실제 값과 예측 값이 일치하지 않는 값을 찾아내는 incorrect_indices 변수에 저장하되,
바로 윗줄의 코드와 다른점은 일치하지 않는 값을 찾는 것입니다.
따라서 윗줄의 코드와는 달리,
논리 연산의 결과 예측 값과 실제 값이 같으면 0 (False), 같지 않으면 1(True) 의 값이 나옵니다.
정확하게 예측하지 못한 데이터의 위치,
즉 세 번째, 네 번째, 여섯 번째, 여덟 번째를 incorrect_indices 변수에 넣습니다.
결과적으로 incorrect_indices 변수에는 인공지능이 정확하게 예측하지 못한 데이터의 위치가 저장됩니다.
8. To check predicted data
이제 정확하게 예측한 데이터의 위치와 그렇지 않은 데이터의 위치를 알게 되었습니다.
그렇다면 그 데이터는 어떻게 생겼는지 확인해 보겠습니다.
실제로 우리가 그 결과를 눈으로 살펴볼 수 있도록
matplotlib 라이브러리를 사용해서 화면에 그래프를 출력해보겠습니다.
import matplotlib.pyplot as plt
plt.figure()
for i in range(9):
plt.subplot(3, 3, i + 1)
correct = correct_indices[i]
plt.imshow(X_test[correct].reshape(28, 28), cmap='gray')
plt.title("Predicted {}, class {}".format(predicted_classes[correct], y_test[correct]))
plt.tight_layout()
plt.show()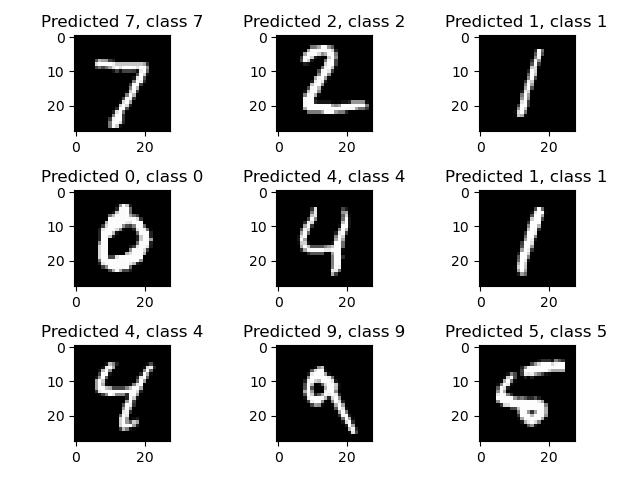
실행 결과를 보면 총 9개의 이미지가 나타나며, 예측한 값과 실제 값이 있습니다.
> plt.figure()
matplotlib 을 사용하여 그래프를 그리려면, 그래프를 그리겠다는 명령을 먼저 수행해야 합니다.
그 명령어가 바로 figure 함수이며, 이를 사용하여 그림을 그릴 준비를 합니다.
> for i in range(9):
파이썬의 for 반복문으로 지금부터 그림 9개를 그립니다.
> plt.subplot(3, 3, i + 1)
for 문의 내부입니다.subplot 함수는 그림의 위치를 정해주는 함수로 세 개의 argument 가 들어갑니다.첫 번째 인자는 그림의 가로 개수이고 (nrows, subplot 의 행의 수)두 번째 인자는 그림의 세로 개수 입니다. (ncols, subplot 의 열의 수)마지막 인자는 순서입니다. (index)
> correct = correct_indices[i]
for 문의 내부입니다.앞에서 만든 correct_indices 배열에서 첫 번째부터 아홉번째까지의 값을 반복할 때마다 correct 변수에 넣습니다.첫 번째 반복에서의 i 의 값은 0이라고 가정하자면, correct 변수에는 정답을 모아 놓은 배열인correct_indices 의 첫 번째 값이 들어갑니다.이 예제에서는 0(첫 번째 숫자 데이터)의 값이 들어갑니다.
> plt.imshow(X_test[correct].reshape(28, 28), cmap='gray')
for 문의 내부입니다.imshow 함수는 어떤 이미지를 보여줄지에 대한 내용을 담고 있습니다.첫 번째 반복에서는 X_test 변수에 들어있는 첫 번째 그림 (correct 변수에 첫 번째 그림을 의미하는 0이 들어있어서)을 가져옵니다.
하지만 이 그림은 각 데이터가 28 x 28 형태가 아니라 각 데이터 한 줄로 늘어선 모습을 하고 있습니다.우리가 처음에 데이터를 한 줄로 바꾸었기 때문이죠.이 형태를 다시 28 x 28 형태로 바꿔 줘야하는데 이때 사용하는 함수가 reshape(28, 28) 함수입니다.그리고 그림을 회색조로 나타내기 위해 cmap = 'gray' 를 입력합니다.
> plt.title("Predicted {}, class {}".format(predicted_classes[correct], y_test[correct]))
for 문의 내부입니다.이는 그림 설명을 넣는 코드입니다.예측한 값을 나타내기 위해 Predicted {(값이 들어가는 공간)}에 예측한 결과값을 format 함수를 사용하여 넣습니다.
> plt.tight_layout()
plt.show()
이제 for문을 빠져나와 화면에 그림을 보여주기 위해 위 함수를 사용합니다.
9. Check for mis-predictions
이제 어떤 숫자를 잘 예측하지 못했는지 살펴봅니다.코드는 앞의 코드, 즉 잘 예측한 데이터 확인하는 코드와 동일합니다.하지만 변수만 잘 예측하지 못한 그림으로 바뀔 뿐입니다.
plt.figure()
for i in range(9):
plt.subplot(3, 3, i + 1)
incorrect = incorrect_indices[i]
plt.imshow(X_test[incorrect].reshape(28, 28), cmap='gray')
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], y_test[incorrect]))
plt.show()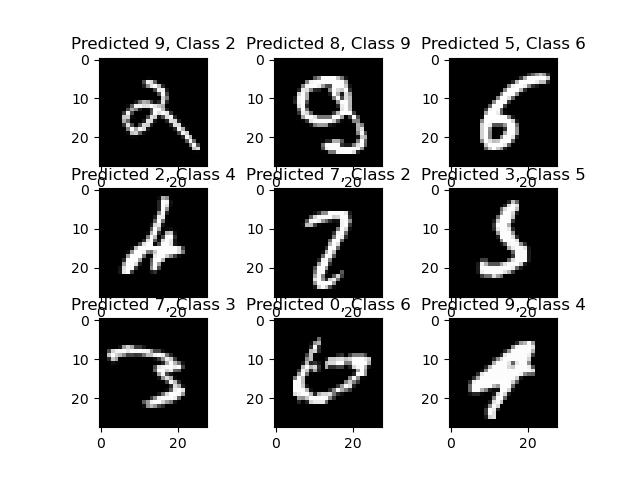
ConvNetJS MNIST demo
cs.stanford.edu
import tensorflow as tf
""" Load DataSet """
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
"""Replace the shape of X in the "mnist" dataset"""
# Adjust Shape (Matrix -> Vector)
X_train = x_train.reshape(60000, 784)
X_test = x_test.reshape(10000, 784)
# Adjust datatype (uint8 -> float32)
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
# Adjust range (between 0 ~ 255 -> 0 ~ 1)
X_train /= 255
X_test /= 255
"""Replace the shape of Y in the "mnist" dataset"""
# Adjust Categorical (in 10)
Y_train = tf.keras.utils.to_categorical(y_train, 10)
Y_test = tf.keras.utils.to_categorical(y_test, 10)
"""Designing an AI Model"""
# Model.(Common)
"""
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(512, input_shape=(784, )))
model.add(tf.keras.layers.Activation('relu'))
model.add(tf.keras.layers.Dense(256))
model.add(tf.keras.layers.Activation('relu'))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax'))
model.summary()
"""
"""
=================================================================
Total params: 535,818
Trainable params: 535,818
Non-trainable params: 0
_________________________________________________________________
"""
# Model. (abbreviation)
model = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(784, )),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 401920
dense_1 (Dense) (None, 256) 131328
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 535,818
Trainable params: 535,818
Non-trainable params: 0
_________________________________________________________________
"""
"""Train a model"""
# Compile
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, Y_train,
batch_size = 128,
epochs = 10,
verbose = 1)
"""
Epoch 1/10
469/469 [==============================] - 3s 5ms/step - loss: 0.2277 - accuracy: 0.9339
Epoch 2/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0835 - accuracy: 0.9745
Epoch 3/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0521 - accuracy: 0.9840
Epoch 4/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0354 - accuracy: 0.9886
Epoch 5/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0273 - accuracy: 0.9914
Epoch 6/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0205 - accuracy: 0.9932
Epoch 7/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0159 - accuracy: 0.9950
Epoch 8/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0168 - accuracy: 0.9944
Epoch 9/10
469/469 [==============================] - 2s 5ms/step - loss: 0.0156 - accuracy: 0.9946
Epoch 10/10
469/469 [==============================] - 3s 6ms/step - loss: 0.0120 - accuracy: 0.9963
"""
"""To check model accuracy"""
score = model.evaluate(X_test, Y_test)
print("Test score : ", score[0])
print("Test accuracy : ", score[1])
"""
313/313 [==============================] - 1s 2ms/step - loss: 0.0703 - accuracy: 0.9817
Test score : 0.07032162696123123
Test accuracy : 0.9817000031471252
"""
"""To check model learning results"""
import numpy as np
predicted_classes = np.argmax(model.predict(X_test), axis=1)
correct_indices = np.nonzero(predicted_classes == y_test)[0]
incorrect_indices = np.nonzero(predicted_classes != y_test)[0]
"""To check predicted data"""
import matplotlib.pyplot as plt
plt.figure()
for i in range(9):
plt.subplot(3, 3, i + 1)
correct = correct_indices[i]
plt.imshow(X_test[correct].reshape(28, 28), cmap='gray')
plt.title("Predicted {}, class {}".format(predicted_classes[correct], y_test[correct]))
plt.show()
"""Check for mis-predictions"""
plt.figure()
for i in range(9):
plt.subplot(3, 3, i + 1)
incorrect = incorrect_indices[i]
plt.imshow(X_test[incorrect].reshape(28, 28), cmap='gray')
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], y_test[incorrect]))
plt.show()'Deep Learning' 카테고리의 다른 글
| CNN (0) | 2022.09.08 |
|---|---|
| Count Objects in Image using Python (0) | 2022.09.06 |
| CNN (0) | 2022.09.05 |
| Basic Tensorflow (0) | 2022.09.02 |
| 7 Segment Display binary connetion table (0) | 2022.09.01 |